Identifying and Eliminating Network Single Points of Failure (SPOF)
In this blog post, we'll go over how to spot and avoid a network single point of failure (SPOF) – a weakness that could take down your entire network.

May 25, 2023
SHARE
Automate your telecom operations
Drive procurement with data, and gain transparency on gaps, waste, and savings opportunities.
“When the going gets tough, the tough learn how to identify single points of failure in a hopefully resilient and diverse network,” sang Billy Ocean.
Ok, we might have paraphrased the lyrics a little, but Mr. Ocean’s ode to resilience perfectly embodies the attitude required for preparing your enterprise network for problems and worst-case scenarios.
Network design plays a massive role in these preparations. An effectively designed network can save you time and hassle, ideally avoiding a single point of failure (SPOF) – a weakness that could take down your whole network.
In this article, we’ll be concentrating on Customer Premises Equipment (CPE) deployment considerations in your Local Area Network (LAN), and we’ll look at some of the usual suspects that should be at the top of your SPOF-hunting checklist.
If you’re looking to get a bird’s-eye view, there are a few articles we published previously that might interest you.
Our comprehensive guide to designing the optimal Wide Area Network for your enterprise, which explains the methodology of WAN design, with a step-by-step hypothetical design process.
The planning principles that should inform your Business Continuity or Disaster Recovery Plan – in the context of Hurricane Ian’s devastating effects on communities and local economies in 2022, this article explores the difference between business continuity (keeping your network operational during a crisis) and disaster recovery (planning to minimize disruption during and after a major outage).
For now, though, let’s go looking for our SPOF a little closer to home – on the LAN.
Finding SPOFs in Your Local Area Network (LAN)
Even when considering the LAN in isolation, there are still several points where things could go wrong, as you can see from this diagram.
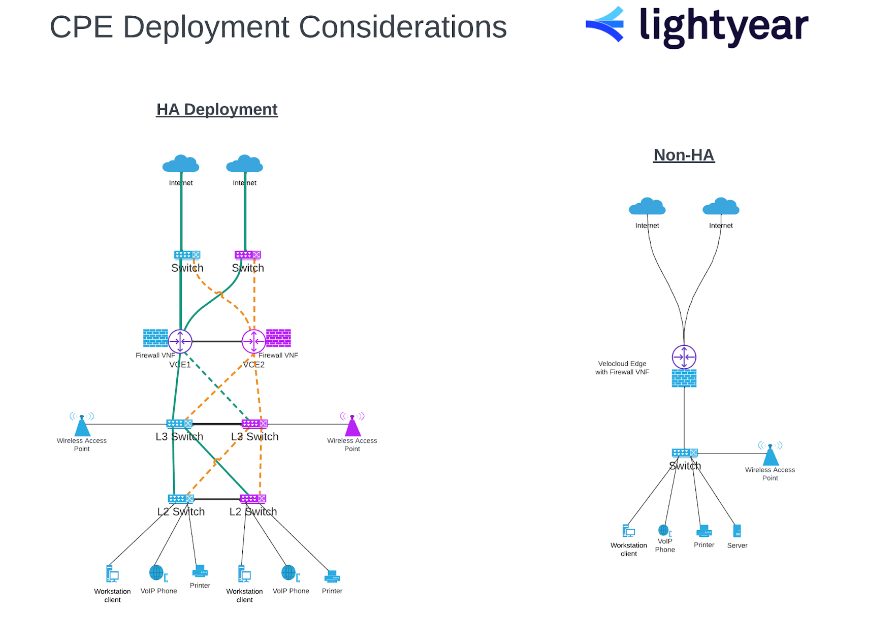
To locate the point of failure, each piece of equipment along the signal path between the user and the WAN must be considered.
A list of typical SPOF culprits would include the following.
Layer 2 switches
Layer 3 switches
Wireless Access Points
Firewalls
Routers
Transport Switches
Although there are many potential points of failure in the LAN, establishing a clear map of the route by which data leaves and enters the LAN should be a straightforward task.
Once the route is clearly marked from point to point, best practice (as illustrated above) dictates you establish a secondary path in High Availability (HA) to eliminate the possibility of a single point of failure with the potential for network-wide outages.
Investigating the signal path is a crucial element of eliminating points of failure – but it’s not the only factor at play. There are peripheral considerations that are just as capable of torpedoing your enterprise network – and like most big, obvious problems, they’re only big and obvious if you’re aware of them.
Power Supply
No, we’re not going to tell you to turn it off and on again. Your mission critical network elements need protecting with HA deployment – but both your primary and secondary circuits need separate power supplies.
It’s still common to see all the enterprise network equipment housed in a standard rack, even at critical network sites – all connected to the same power supply (including the HA equipment).
Referring to the CPE deployment illustration above, as a rule of thumb, the purple and blue network elements should never be powered by the same source.
Good network design comes to the rescue, as always – trace back your power supply as far as is possible/practical and include power diversity with the following equipment.
Battery backup units
Power outlets
Breaker panels
Businesses looking for even greater resilience in their power supply could also consider the following.
Dual power service providers (although this service isn’t commonly available)
Generator power
Green alternative power (such as solar PV or wind turbines) that can be connected to an upstream battery array
Automate your full telecom lifecycle
Heating, Ventilation, and Air Conditioning (HVAC)
Just like human beings, enterprise network equipment has optimal temperature conditions. It’s often equipped with sensors to detect extreme temperatures, switching itself off when it can’t stand the heat (or the cold).
Consequently, you need to add air conditioning to the ever-growing list of additional equipment you’ll need to diversify. That is, unless you want to spend thousands of dollars and hundreds of hours designing the ultimate HA redundancy network, doubling up across your WAN, LAN, and power supplies – only to have everything in your telecom closet shut down because you only bought one air-conditioning unit and it broke.
If you’re doing it properly, aim to install dual air-conditioning units. And make sure they’ve got separate power feeds!
Network and Physical Security
Network security. It shouldn’t come as a surprise to anyone working with enterprise networks that cybersecurity issues represent a real threat to the integrity of your network.
While the trend towards hybrid working has created many cybersecurity complications, there are still accepted measures that should be part of any ongoing cybersecurity precautions.
Robust perimeter security (such as firewalls or secure web gateways), Zero Trust Network philosophy, and regular cybersecurity awareness training for all employees are all modern enterprise network security essentials.
While effective cybersecurity can occasionally feel like overkill, it’s an area where it’s better to be safe than sorry – a single compromised user or network component (such as a domain controller) with elevated admin access rights could potentially put your entire network out of action for days or even weeks. Continually updating your cybersecurity policies and maintaining a structured, vigilant approach will help you identify and avoid these threats.
Physical security. Physical threats to your network equipment are mercifully rare – if access is limited only to trained individuals with good reason for interacting with the gear. However, limitations within the built environment may prevent equipment from being kept physically secure.
One incident which sticks in our memory here at Lightyear was caused by a careless decorator. Tasked with decorating the client’s corporate offices, the enthusiastic painter neglected to use a drop cloth over the network closet. As a result, when he knocked over a tin, a gallon of fresh paint spilled directly into the core network equipment rack, causing a massive outage. “Chanterelle Beige” servers – and some very red faces. Not a good look.
Servers and Applications
Whether they’re on-site or in the cloud, both servers and apps represent potential failure points. Again, if they’re mission critical, a primary and a secondary is the bare minimum for your network.
And make sure your secondary server or app is aligned with your secondary circuit, too – no point having both primary and secondary servers running on your primary circuit if your primary circuit goes down, is there? Aim for as much network and geographical diversity as possible.
Skills and Knowledge
Another people problem – an employee doesn’t always need a tin of paint to put a dent in your network. Hoarding vital information about the network is probably an even greater risk.
“They just dragged Jimmy from IT away in handcuffs! Hope someone else knows the passwords…” We’re dramatizing for effect, but you get the picture. Network administrators are critical to the health of enterprise networks. If you’ve got a “super user,” you should back them up as well, and create a succession plan should they leave in a hurry.
It’s a thousand times easier to document and plan succession, than to try and manage a fully functioning enterprise network that you’ve never been involved with at the admin level.
Regular Redundancy Testing
Identifying SPOFs is, unfortunately, not just a “one-and-done” exercise. Your network doesn’t stand still – introduce human users and other complications, and you’ll find that when people start changing stuff (plugging their own equipment into the network, and so on), changes can occur in the network that won’t necessarily get communicated back to the admin.
As part of your ongoing network vigilance, you’ll need to schedule regular full redundancy testing, to make sure any user-led changes haven’t created a potential single point of failure.
Drilling down for SPOFs on the LAN this way should have given you a good awareness of how different factors can interact to cause you problems. Taken alongside the blogs linked at the top, this overview should help you put some solid SPOF-finding strategies in place for your LAN.
If you’d like to dig a little deeper, get a little help sourcing all this redundant circuitry and equipment, and develop a network-wide watertight process to defend your network, get in touch with us here at Lightyear. Our automated procurement platform is backed up by a team of industry professionals who can answer all your questions (including advice about cleaning paint out of servers).
Featured Articles
Want to learn more about how Lightyear can help you?
Let us show you the product and discuss specifics on how it might be helpful.
Stay up to date on our product, straight to your inbox every month.