Network Redundancy vs. Diversity: Building a Resilient Network for Maximum Uptime
Learn how network redundancy and diversity work together to maximize internet uptime, prevent costly outages, and future-proof your business connectivity.

Jun 17, 2025
SHARE
Automate the telecom lifecycle
Get better quotes, launch sites faster, keep inventory accurate, and control spend.
Network redundancy and network diversity are two different, if not complementary, concepts, which can be a little confusing. Though both help to accomplish a common goal, they aren’t synonyms. It’s important to understand the differences, similarities, and contributions each makes to the wide area network (WAN) environment.
Redundancy vs. Diversity: What’s the Difference?
Let’s start by breaking down the two concepts.
Network redundancy is the presence of duplicate elements within a network infrastructure. It ensures continued operation and reliability in the event of a failure or disruption.
Network diversity, on the other hand, involves the use of distinct and physically separate paths, technologies, or providers for network connections. This enhances its reliability and resilience against failures, including natural disasters or intentional attacks.
As you can see, both facilitate network continuation, but in different ways. To ensure they can keep operations running, many businesses and organizations create high availability networks through redundancy — multiple internet connections that are in place if one should fail.
Software-defined wide area networks (SD-WANs) and modern firewalls make it easy to monitor load balance and failover between different connections automatically. When there’s a failure or excessive demand on one network, the other manages necessary workloads — and users often never know there have been changes behind the scenes to keep them working.
Redundant Internet Access Considerations
There are two things to consider with redundant internet access, physical diversity and network diversity.
Physical diversity refers to separate physical connections between a building and an internet service provider (ISP). One option for a redundant system connecting both through a telephone company and a cable company. Although those two modes of connecting to the internet don’t share infrastructure, they can, however, be similar enough not to provide adequate redundancy. For example, if utilities are cut off during severe weather or if a traffic accident damages a utility pole, neither physical connection may work.
Unfortunately, sometimes even the most effective physical diversity strategy alone can’t guarantee high internet service availability, which is where network diversity comes in. The CenturyLink/Level (3) outage is a prime example. In August 2020, traffic dropped nearly to zero, potentially impacting their service across all 50 states. When there is a large issue such as this, carriers that share backbone elements and interconnected points with upstream providers can be impacted. Physical connectivity may still be functional, but internet traffic can’t get through across the public internet.
To maintain internet availability, an integrator can use PeeringDB and ASRank ranking tools to determine networks’ shared elements, peering (the ability to connect and exchange traffic), and routing. This information lets you choose diverse networks with different peering relationships and create true redundancy that results in continued availability if an event such as the CenturyLink outage occurs.
Even if the building you work out of has a limited number of access providers (fiber, coax, etc.), you likely aren't limited to these companies to order your internet service. In many cases, a carrier with physical access in a building will lease their fiber or transport to another carrier, who can actually become your ISP. This is often done transparently to the end users, with the lit carrier providing a physical layer 2 connection that allows the chosen ISP to reach your office. With a little research up front, these options can be architected to optimize availability and routing.
Why Resilience Matters
Simply put, internet access downtime is very costly for most businesses. According to some estimates, IT downtime can cost businesses north of $5,600 per minute.
Although that may seem surprisingly high, when you factor in potential lost revenue (if you’re a shipping business, downtime means you’re not shipping packages!), the opportunity cost of reduced productivity (workers can’t get work done), and any costs of getting things back up, the headline number begins to make more sense.
The cost and risk of downtime will of course differ from business to business, but there’s almost no business out there where downtime isn’t costly. With that in mind, taking time to evaluate redundant and diverse networking options for your business and paying a little more to ensure your risk of downtime is exponentially lower likely makes economic sense.
Picking the Right ISP for Your Redundant Internet
We recently explored the differences between Tier 1, Tier 2, and Tier 3 ISPs and how to decide which tier works best for your business. Understanding how the different tiers operate is useful when procuring an effective redundant internet solution.
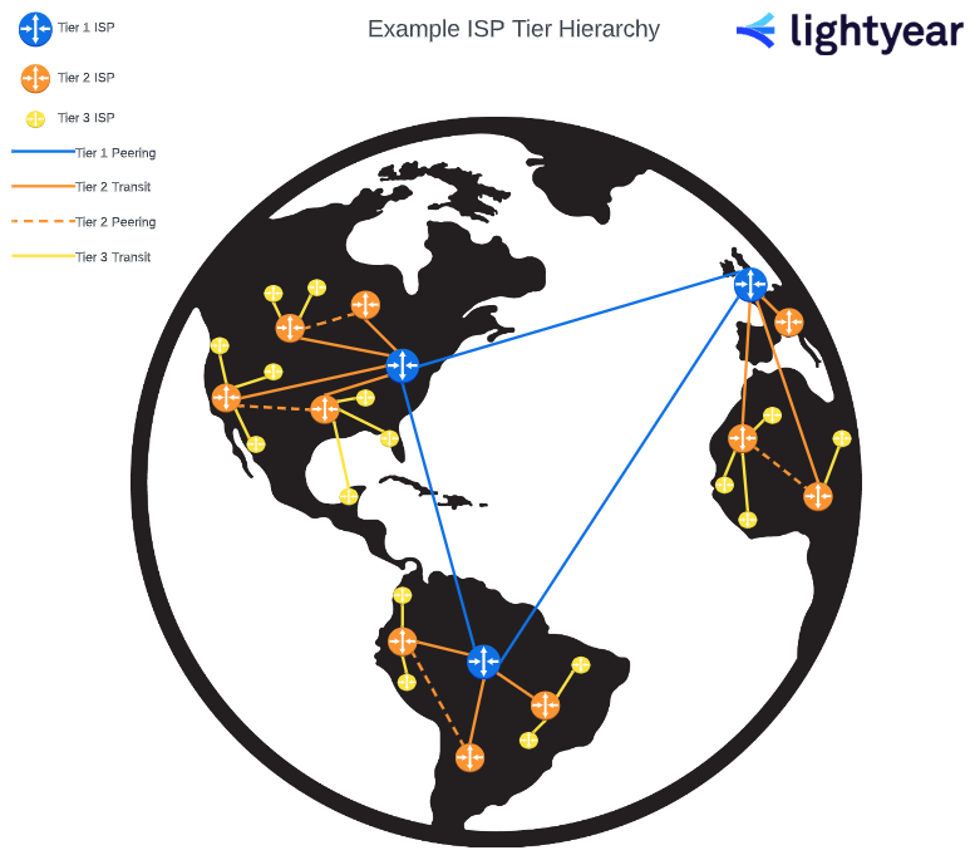
A Tier 1 ISP (which owns the physical network of your entire region) is unlikely to give you any surprises when your circuit meets the LAN. If you’re with AT&T, for example, it’s more than likely that AT&T will be your carrier in the last mile and the middle mile, too.
Tier 2 ISPs are carriers that purchase internet transit from Tier 1 providers but also peer directly with other networks to exchange traffic. This hybrid approach allows the potential for better pricing than Tier 1 ISPs, while still maintaining relatively strong routing performance.
However, if a Tier 3 ISP (who is basically renting lines from Tier 1 and Tier 2 ISPs) provides your redundant internet circuit, then you’ll have to do some snooping. If a Tier 3 is running its LAN on AT&T infrastructure, then your redundant internet isn’t redundant at all. If AT&T goes down, so does your redundant circuit.
If you’re planning on using Tier 3 ISPs in your business continuity plan, be prepared to ask a lot of questions (and get some complicated answers). You’ll need to find out who’s providing the circuits right across the LAN.
Continuously optimize your network
Key Redundancy Strategies for High Availability
When you’re looking to create redundant internet, there are best practices that can be adopted. The same methodologies that carrier networks use to ensure their provision is robust will work equally well for enterprise business communication builds, too.
N-modular redundancy is the commonly accepted lingo used to describe various levels and types of redundant internet circuitry (as well as more generalized systems planning). Though it may look like yet another example of IT jibber-jabber, it’s a neat shorthand that makes things much clearer and easier to understand.
It looks a little like algebra, but the three main concepts — minimum functional system, additional backup, and additional independent system — are easily identified.
N = the bare minimum required for the system to function;
N+1 = the addition of a backup system to N (“backup” defined here as non-functional, unless there’s an emergency);
N+(X) = the addition of multiple backup systems, with several backups represented by X;
2N = two fully capable independent systems;
2N+(X) = two fully capable systems, each with several backup systems;
XN+(X) = represents the idea of ongoing expansion of your redundancy plans.
Likely, budget limitations will dictate the amount of redundancy you incorporate into your systems.
It would be wise to carefully weigh the financial cost of each layer of redundancy against how much real-world flexibility that additional layer will bring, in the event of a disaster or extreme situation. Beyond a certain level, the probability that a redundancy layer will ever be used diminishes.
Redundant Hardware and Routing Protocols
When planning redundancy into a network topology, redundant hardware systems should be at the top of your list. The most redundant hardware systems are set up in high availability (HA), ensuring automatic failover. Several equipment protocols have been established to assist with these HA topologies. Of note are Cisco’s Hot Standby Router Protocol and Virtual Router Redundancy Protocol.
The primary goal in HA topology is to enhance the fault tolerance of the WAN by eliminating a single point of failure for the routing devices. When two devices are set up in HA, if the primary device hardware fails, the secondary HA device will automatically become primary and take over.
Other topologies aren’t automatic but still offer redundancy protections, such as a cold standby, where the backup device is on-site but inactive until needed. Another option is a warm standby, where a backup device is partially online and can be inserted into the network faster.
Several routing topologies also offer some form of redundancy. For dedicated internet services, for example, Border Gateway Protocol routing allows for the rehoming of public IP addresses between different paths. Ring and star topologies also offer redundancy through multiple path options.
N-Modular Redundant Internet Path Examples
So, what do these different N-modular redundant internet paths look like as circuits? Here are some diagrammatic examples of the redundancy formulae we introduced above.
N = internet from a single service provider, via a single router.
N+1 = the same circuit but with a backup circuit (notice that the backup follows the same route, with the same service provider and router equipment).
2N = two separate circuits, with two redundant ISPs and two redundant routers.
Notice that in the 2N example above, redundancy ends at the organization’s firewall — so both circuits are forced to use the same path through the local area network (LAN).
This doesn’t have to be the case, though — it’s possible to procure redundant internet circuitry all the way to the endpoint, depending on your budget and your organizational needs. Here’s what that looks like.
However, if you’re planning to extend your redundant circuits in this way, it’s important to thoroughly research your ISPs, and find out exactly what’s happening upstream.
Managing and Preventing Downtime with SD-WAN
SD-WAN adoption has accelerated over the last few years, in part because it makes managing and aggregating multiple ISP circuits easy. In fact, many single-site enterprises (or multi-site without the need for a WAN) opt to deploy SD-WAN for the sole purpose of providing load balancing and failover to optimize site uptime and internet availability.
Many SD-WAN solutions provide constant circuit monitoring, oftentimes including multiple health checks for packet loss, latency, and jitter each second. If the SD-WAN appliance deployed onsite detects an ISP gateway failure, or even degradation of one of the underlying ISP circuits, it will automatically reroute traffic to a better path if one is available.
Additionally, there are cloud-based SD-WAN solutions that measure all of these same metrics at a local level, but also proxy all of your traffic through their networks. If they detect a network-based outage, peering or otherwise between upstream providers they often have the ability to route around these issues.
Redundancy Is Complex but Necessary
Building a resilient network is complex, but the cost of not doing so can be much greater. By investing the time to build both redundant and diverse internet connections, businesses can protect productivity and adapt more effectively to unforeseen challenges.
Interested in discussing your redundancy, diversity, or uptime strategy more broadly? Request a meeting with us at Lightyear.
Featured Articles
Want to learn more about how Lightyear can help you?
Let us show you the product and discuss specifics on how it might be helpful.
Stay up to date on our product, straight to your inbox every month.